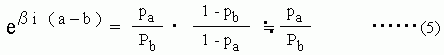乮徹柧乯
乮侾乯幃偼椉曈偺忢梡懳悢傪偲傞偲丄師偺傛偆偵曄宍偝傟傑偡丅
log y1 = log K 亄 bxog a 丒丒丒丒丒丒乮係乯
偙偙偱丄倶 偺曄壔検偑 1 偢偮曄傢傞僨乕僞傪峫偊傑偡乮偙傟偑婎弨曄峏偺崻嫆偱偡乯丅偦偆偡傞偲倶偑旝彫検 侾偩偗憹偊偨帪偺乮係乯幃偼 乮俆乯幃偲側傝傑偡丅
log y2 = log K 亄 bx亄1og a 丒丒丒丒丒乮俆乯
椉曈偵偮偄偰偦傟偧傟嵎乮俆乯亅乮係乯傪偲傝傑偡丅嵍曈傪仮log y 偲偍偔偲
仮log y = log y2 亅 log y1 = bxog a ( b 亅 1 )
乮係乯幃傪戙擖偟偰 x , a 傪徚嫀偟惍棟偡傞偲
仮log y = ( 1 亅 b )log K 亅 ( 1 亅 b )log y1 丒丒丒丒丒乮俇乯
乮俇乯幃偼乮俀乯幃偲摨偠丅徹柧嵪両
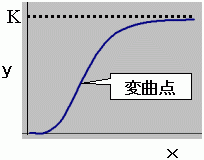
b 傕 K 傕掕悢偩偐傜丄乮俇乯幃偼仮log y 傪栚揑曄悢偲偟偰log y 傪廬懏曄悢偲偡傞夞婣幃偵側偭偰偄傞偙偲偑傢偐傝傑偡丅倶 偺曄壔検偑 1丂偢偮偺応崌偺僑儞儁儖僣嬋慄側傜夞婣寁嶼偱學悢傪媮傔傞偙偲偑偱偒傞偙偲偑徹柧偝傟傑偟偨丅
曄悢偑摍娫妘偱偺曄壔検側傜偽丄曄悢曄姺偟偰曄悢傪侾偢偮曄壔偡傞検偵曄姺偟偰偍偗偽偙偺曽朄偐傜嬤帡幃傪摼傞偙偲偑偱偒傑偡偹丅
乮崿棎偟側偄傛偆偵乯
乮俇乯幃偐傜 b , K 傪媮傔傞偲偄偆偙偲偼丄嵟弶偺廬懏曄悢 x 偼侾偢偮曄壔偡傞偙偲傪慜採偵偟偨嬤帡幃偱偁傞偙偲偵側傝傑偡丅偳偺傛偆側廬懏曄悢 x 僨乕僞傪帩偭偰偙傛偆偑娭學側偄偲偙傠偱丄 x 偑 1 偢偮曄壔偟偰偄傞偲偒偺僔僌儌僀僪宍忬偲偟偰栚揑曄悢偩偗偱寁嶼偝傟偰偄傑偡丅
偟偐偟偁側偨偑抦傝偨偄偺偼娤應偟偨曄悢偲栚揑曄悢 y 偲偺娭學偱偡偹丅嵟弶偺僔僌儌僀僪嬋慄傪堷偒怢偽偟偨傝埵抲傪偢傜偟偨傝偟偰偁傢偣傞嶌嬈偑巆偭偰偄傑偡丅
偩偐傜偁側偨偼丄侾偢偮曄壔偡傞 x 偲丄偁側偨偺娤應偟偨摍娫妘偺廬懏曄悢偲偺娭學幃傪媮傔偰戙擖偡傞偙偲偵側傝傑偡丅
偱傕偙傟偩偗偱偼丄僔僌儌僀僪偺宍忬偑寛傑傞偩偗偱偡丅傑偩丄偁側偨偑娤應偟偨僔僌儌僀僪嬋慄偺埵抲 a 偼寛傑偭偰偄傑偣傫丅僔僌儌僀僪嬋慄偺埵抲偼 x = 0 偺埵抲偵懳墳偡傞栚揑曄悢偺抣偐傜曽掱幃偱嶼弌偝傟傑偡丅 x = 0 偺埵抲偼幚愌僌儔僼傪昤偒丄曄嬋揰傪壗傜偐偺曽朄偱悇掕偡傞傢偗偱偡丅僞僐偺曽朄偼廬懏曄悢傕娤應僨乕僞偑偽傜偮偔偙偲傪梊憐偟偰丄曄嬋揰嬤朤偺3揰偺僨乕僞偼捈慄偱偁傞偙偲傪慜採偵偦偺3揰偺栚揑曄悢偺暯嬒抣偱悇掕偟偰偄傑偡丅
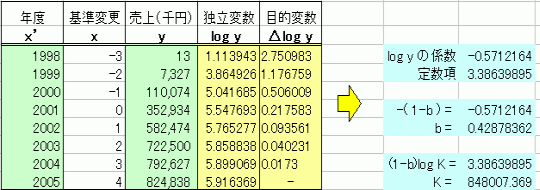
乮侾乯幃偵 K丂偲 b 偲偺悢抣傪戙擖偟偨幃偐傜僄僋僙儖側傜丄僑乕儖僔乕僋偱媮傔傞偙偲偑偱偒傑偡丅
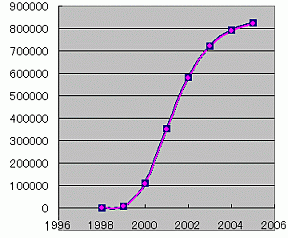
捈慄偵側傞偼偢偺偁偨傝偺僨乕僞偑偁傑傝偵偽傜偮偄偰偄傞偺側傜丄庤偱僔僌儌僀僪僇乕僽傪彂偄偰曄嬋揰傪栚偱尒偰悇掕偡傞偲偄偆尨巒揑側傗傝曽偑幚柋揑側嬤帡偵偼桳岠偱偡丅敪昞偵偼晄岦偒偱偡偑丅
丂