|
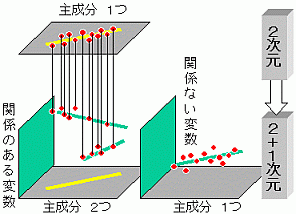
元のデータで3次元散布図を作って考える
多くの人が、主成分分析をしたら安心してしまって、もう一度その結果から元のデータの散布図を作って考えるということをあまりやらないようだね。
外部にものごとを発表しようとする場合に、もう一度この確認作業を行うことを強く勧めます。
コンピューターに見えている多次元空間のデータの散布状態は、3次元の空間しか理解できない我々人間にとってやはり難物だと思います。
なぜなら、こう書いている私も、一般的な主成分分析の解析方法で判断した後、レポートを書こうとしてもう一度散布図を描いてみたところ、何度も判断の基本的な考え方の部分で修正した経験があるからです。事例で示そうね。
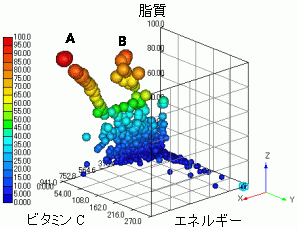
右のグラフは、3次元のバブル散布図です。日本食品標準成分表の分析値のうち、
x : エネルギー
y : ビタミン C 含量
z : 脂質含量 の散布状態を示しました。
この3因子はあてずっぽうで選択したのではなく、主成分分析をすると同時に算出されてくる因子負荷量の大きさから機械的に選択されてきたものです。 すなわち、表 1 から第4主成分 がエネルギーと脂質とビタミンC との関係があるよと教えてくれています。
この情報から、 x , y , z にする変数を機械的に選んだだけです。
上から見ている遠近感を表現するため Z 軸の上のほうが球の直径が大きくなっています。 さて三次元バブル散布図をよく見ると、 A と B との2つの平行な別の関数関係があることがわかります。
さらに、ここでこのグラフを回転できないのが残念ですが、回転させるとBの方はビタミンCとの関係があり、Aには関係ないことが読み取れます。 主成分分析でキャッチした第4主成分とは、コンピューターはBのほうの食品グループの特徴を指摘していたわけです。主成分分析だけで議論している人は、Aも含めて議論しますから、本当のところは知らずに議論していることになりますね。 さっそく、この二つを層別して二つを分けている要因を調べたいですよね。フリーソフト Graph-R の出番です。バブルをクリックするだけで、その元データ(X,Y,Z 値)が記録されてゆきます。これをファイルにすれば層別終わりです。すごいね。 A,Bを層別抽出できたら、重回帰分析で、量的関係が近似式で把握できます。これだけでも報文が一つ出来ますね。 残念ながら、主成分分析結果だけからは、この情報をキャッチできなかったわけです。主成分分析の後、再び元のデータに戻って考える重要性はここにあります。主成分分析が平行な関数関係や、細かい凹凸を分離して表現してくれるわけではないのです。
また、散布図を併用しないかぎり、曲線の関数関係を発見してくれるわけでもありません。
日本食品標準成分表の結果を、この先の検討をするつもりはありませんから、どうぞどなたか検討を継続して発表して下さいね。
主成分分析を情報集約の手段として使い、「新たな指標としてこんなものが考えられる」
という程度の報告なら問題は少ないのです。しかし時代はもう少し踏み込んで、主成分分析から様々な現象のメカニズムを考える所にきています。
そこまで踏み込むと、公表する前に、少なくとも3次元レベルまでの散布図で確認を取り、自分が考えているメカニズムの内容を見直す必要があります。
そのことは、3つのメリットがあります。
- 3次元の散布図を作って、主成分分析結果と付き合わせることで、データの分布状態の より新しい側面を発見できる。解析レベルがより深くなります。
- 公表した後で修正するより、公表時点で深い洞察を示す方があなたの学問レベルの信頼感をより増幅してくれます。同じ手間なら、後始末より前始末。
- 多くの場合、次に追求すべき世界が見えてきます。
カラーの3次元バブル散布図は綺麗だから、あなたの報告に眼を通してくれますよ。
3次元での解析にはほかにも、等高線図(コンター)を作成したり、カテゴリーデータなら層別散布図を作ることでかなり現実に肉薄できます。
エクセルでもすぐにできますから試してみてください。(おまけ−エクセルでの散布図作成手順)参照。
点による3次元散布図では、せっかく散布図を描いても点には影がないため前後関係や上下関係が読み取りにくく立体感が得られないため情報を読み取りにくいものです。Z方向に線分を立てる工夫も見られますが、これとて多数の点が入ると何がなにやら分からなくなります。この理由から、あまり3次元散布図は使われてきませんでした。
3次元バブル散布図は、この欠点を克服しています。人にわかりやすい俯瞰図としての空間散布状態を、あたらしい表現方法で示してくれます。
バブルとは泡。観測データの点の位置は誤差を持つわけですから、観測点から球状のある範囲で真のプロット場所があるはずです。このバブルの球半径がどれくらいが正しいかをここでは問わないこととして、バブルの陰線処理とZ軸方向で色分けすることで、かなり複雑な形状の分布を人間が読み取ることが出来ます。
≪エクセルのバブルチャートとの違い≫エクセルのバブルチャートは基本的には2次元の散布図です。3次元の大きさを円の直径で表す表現方法ですから、伊藤さんの3Dバブル散布図とは考え方が異なる表現です。
伊藤さんのものは3次元散布図です。俯瞰図で見るときに近いほうを大きく見えるようにして遠近感を表現したものです。また手前にあるバブルの向こうは陰になって見えないようにしてあります(陰線処理)。見る視点を変えられるところがすごいです。
Graph-Rの3次元バブル散布図でもバブル同士が離れてしまって、点による3次元散布図とあまり変わらない状況の散布図のときは、立体形状に言及するにはデータが少ないなあと考えてたほうがよいです。
それでもZ軸の色情報と、3軸の回転表示を併用すると、想像で空間をうずめることくらいは出来ますから散布図を描くことは必要です。報告の中での主成分分析の結果について、断定のしかたが判断できますからね。 このグラフ表現方法は多分これから、プレゼンテーションの新しいジャンルを形成すると思います。
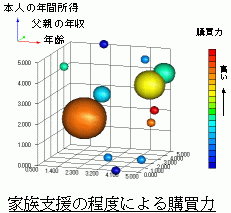 3次元バブル散布図は幸いなことにフリーソフトで提供されています。伊藤徹さんがつくった、 Graph-R というソフトです。
3次元バブル散布図は幸いなことにフリーソフトで提供されています。伊藤徹さんがつくった、 Graph-R というソフトです。
似てる名前のソフトがあるから間違えないでね。すぐにシェアウエアになるでしょうから、今が導入どきです。出来れば、今のバージョンくらいは貧乏なタコ人のためにフリーで置いておいてほしいですね。
さ・ら・に、史上初!
エクセルでは作図できない4次元ポートフォリオ図が描けるぞ。球で表現すると迫力がおおきい。sample23.csv を使ってやるとできます。3次元ポートフォリオ図だって可能だよ。 いろいろな種類の3次元グラフの美しいカラー表現が出来ます。グラフが回転できますから、とても有用なソフトです。
いろいろ表現形式があって、Graph-Rの作品コンテストでもしたいくらいだ。
もっとこのソフトの素敵なところがあります。バブルの一つにポインターを合わせてクリックすると、
その x , y , z の位置の数値を表示してくれます、異常値の発見とか、層別する要因の発見なんかやりやすいですね。(正確に中心を押さえないとだめ。点表示がよい) 主成分分析の利用という視点からだと、三次元バブル散布図がお勧めだけど、Graph-Rは関数式から三次元の等高線が描けたり他にも多彩な表現方式があります。グラフの見本は伊藤さんのホームページで見ることが出来ますよ。おススメ! 伊藤さん、素晴らしいソフトをありがとう。ダウンロードもここから入れます。
 http://www.iris.dti.ne.jp/~tohru/index.html http://www.iris.dti.ne.jp/~tohru/index.html
Graph-R の3次元バブル散布図の作成マニュアル
- エクセルで自分のデータを3変数の一元表で入力しておく
- GraphR178.lzh をダウンロードし、解凍して出来たフォルダー GraphR178 のなかに sample002.csv のファイルがある。通常ならエクセルのアイコンになっているはずだ。
- Graph-R はこのsample002.csvの様式で入力していないと散布図を書いてくれないから、sample002.csv の中に君の3変数データをコピー&ペーストして貼り付けよう。
君のエクセルファイルからデータ部分だけコピーし、sample002.csvの A4 の位置をフォーカスしてデータを張りつけます。前のデータがはみ出して残っているかもしれないので反転しているうちに下のほうをチェックしようね。エクセルの中の多くの変数から3変数を選択して貼り付ける方法は、3章のTipsに入れていますからそちらを見てね。
- 君の好きな場所に、「名前を付けて保存」しよう。
互換性がないけどどうする?と聞いてくるからそのまま Yes を選択。保存されます。
いったん、君のファイル ***.csv ファイルを閉じてしまおう。
- アイコンクリックして Graph-R を立ち上げます。
- とりあえずの散布図作成。
フォルダアイコンをクリックすると Open で通常どおり君の保存したcsvファイルを選択をします。すぐにとりあえずの散布図が出てきます。
- 異常値が見つかることもあるから、どの数値のことか確認してみましょう。
右人差し指アイコンを押し込みます。この状態でいろいろな点をクリックしてみましょう。
クリックした点のx、y、z値が、「選択データ」ウインドウに書き込まれてゆきますから、「クリップボードにコピー」すればとりあえずメモ帳などに貼り付けて、君の ***.csv ファイル内にある異常データ削除などの作業につなげることが出来ます。ここの「削除」ボタンはこのウインドウ数値のクリアという意味で ***.csv ファイルから直接データ削除することではありません。
- 設定を変えて、3次元バブル散布図にしよう。
白いタブつきフォルダーのデザインのアイコン「設定」を押し込みます。「設定」ウインドウが開きます。グラフの種類プルダウンメニューの▼ボタンを押すとバブル発見!バブルを選択してOKボタンを押します。あーら、素敵なバブル散布図に変身。
- では散布図を回転させてみようか。
両矢印が丸くなっている一見イヤホン風のアイコンを押し込もう。画面内の白い所でもいいから、マウスの左ボタンを押したまま、ドラッグしてみて。最初の状態に戻すには立方体マークの「位置リセットボタン」を押すだけ。楽しんでみてね。
- デザインしようか。
Z 軸の虹色スケールもボタンを押し込むことでいろいろ希望の位置、大きさに出来ますね。3軸方向も動かせます。画面内に文字を書き込むことは出来ません。
パワーポイントなどに貼り付けて軸の凡例を文字で入れ込む場所を想定してデザインしてみてください。
- 2次元散布図にする。
となりのXYアイコンなど希望のものを押せばよいです。
- 画像保存する。
画像保存ボタンで pngファイルや jpgファイルに保存できます。
他の方法として、一般に Windows では、ALT + PrintScreen でフォーカスされているウインドウのイメージをクリップボードにコピーします。これをPhotoshopや、PowerPoint、IrfanView(フリー、お勧め)などのソフトに貼り付けてファイルにする方法を覚えておくと便利です。貼り付け方法はドローソフトを立ち上げてから Ctrl + V 。
- 等高線図など他の表現にはsample00*.csvの * の番号を選択することでおこなわれます。
- エクセルを使わずに、添付されている Sample002.csv ファイルに入力して、入力シートをCtrl+Aでシートごとクリップボードにコピーすると、GraphーRの「ファイル」からクリップボード渡しもできます。
| 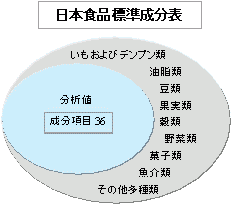 上記分析値に同じ日本食品標準成分表のカテゴリーデータをダミー変数として加え たデータから主成分分析をする。
上記分析値に同じ日本食品標準成分表のカテゴリーデータをダミー変数として加え たデータから主成分分析をする。