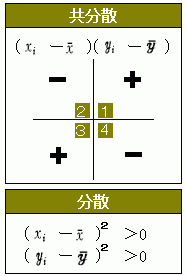
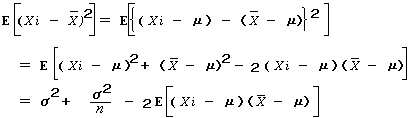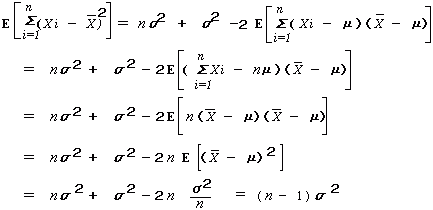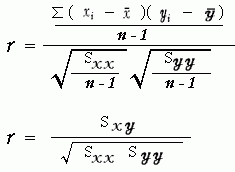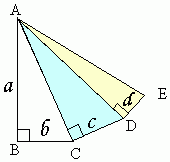 ばらつきを四則演算するには、二乗(または平方)の値で行われるということを知っておかなければいけません。効果の四則演算は、情報量(二乗)で行われます。 ばらつきを四則演算するには、二乗(または平方)の値で行われるということを知っておかなければいけません。効果の四則演算は、情報量(二乗)で行われます。
データがばらつくということは多数のコントロールできない因子の微小な効果分がデータの大きさに影響させているためにばらつくのです。 右図は、例としてデータに影響を与える4種類の因子がどのように標準偏差に影響するかを図示したものです。
4種類の因子の与える影響の効果を a 、 b 、 c 、 d の大きさとします。効果 a に、 b の因子によりばらつきが増えるとすると、
a2 + b2 の値、すなわちピタゴラスの定理でAC2 になります。すなわち a 、 b のばらつきが合わさると AC の効果の大きさでデータがばらつくのです。同じように、 a 、 b 、 c の効果が合わさってばらつきになれば、AD の効果になるのです。 a 、 b 、 c 、 d なら AE が4種のばらつき要因が重なったときに観測される標準偏差になるわけです。 効果はマイナスにも作用しますので、観測データは平均値に対してプラスとマイナスの両方に分布しますから正規分布になります。しかし、ばらつき因子が増えると、標準偏差は増加する方向にしかならないことがこのピタゴラスの定理の連続の絵で理解していただけると思います。
多変量解析が、普通の分散分析と何か違う特別のものと考えている方もいると思いますが、情報量で取り扱うやり方が変わっているわけではありません。取り扱う変数の数が多くなっただけです。
この世の中は二乗の世界でデータが見えているのです。ピタゴラスの定理の連続がばらつきの世界でもあります。物質の原子構造はデジタルの世界ですが、現実の社会で観測されるデータでは、無数のばらつき要因が重なった結果なので、いろいろの観測値が定量値として連続したように見えるわけです。
ばらつきの四則演算の応用計算 −− 分散の加法性 計算例 −−
分散の加法性(加成性)の公式と説明 (設問)
トランプの箱を設計したい。トランプの厚みの分布はmm単位で N( 0.5 , 0.012 )である。トランプにはジョーカー2枚入れて全部で54枚をひとつの箱に入れる。54枚重ねたときの厚みに、標準偏差の3倍を余裕しろとしてスペースを空ける。箱の厚みはいくらにすればよいか。
( 興味があれば見て )・・・・再クリックで閉じる
(計算)
ばらつきが54枚分重なるから、全部重ねたときの厚みの分散は次のように計算される。
分散 = 0.012 + 0.012 + ・・・・・ + 0.012 (54個の足し算)
= 54 × 0.012
= 0.0054 = 0.07352
トランプセットの厚みの分布は次のとおり。 N( 0.5 × 54 , 0.07352)
3σ = 3 × 0.0735 = 0.221 mm
よって
箱の厚み = 0.5 × 54 + 0.221 = 27.221 mm
分散が足し算されるという性質を分散の加法性といいます。実務性の高い性質です。たとえば、1000本入ったくぎの総重量をばらつきをいれて考えるとか、平均値のばらつきはいくらになるのかとか、3本のタンクの溶液を混ぜると濃度のばらつきはどれくらいになるかとかいった利用法が実際に使われています。
分散の期待値を V( x ) と表現しよう。ばらつきのある変数 X , Y の分布は次であったとする。
N ( X ,σx2 ) 、 N( Y , σy2 )
次の計算式で算出される値のばらつきはいくらになるか。
X + Y → V( X + Y ) = σx2 + σy2
X − Y → V( X − Y ) = σx2 + σy2
引き算でも分散は足し算ですね。間違いではないんですよ。平均値が増える方向でも減る方向でもばらつきはそれまでより増えるという性質です。
ただし、映写機のフィルムの大きさのばらつきとスクリーンに映る画面のばらつきは相似計算になるため上記の式は当てはまらないから注意してください。 カードの厚み場合は、一枚のカードのばらつきが拡大されるわけじゃないから足し算です。映写機では画面上の枠長のばらつきは拡大比率に従って拡大されるから掛け算になります。掛け算の式は要注意ということです。 じゃあトランプから10枚カードをとったときはばらつきが増えるの?という疑問が出ます。 ばらつきは減ります。なぜなら、44枚分のばらつきを計算するのと同じだからです。
引き算のばらつきが増えるというときは次のようなケースと考えてください。
3枚のうすい木の板を製造して張り合わせ、最後に厚みを調整するときに2回に分けて板を削ったときにそのばらつきはどうなるか?という問題です。
板の厚みのばらつきと、張り合わせのばらつきが加算されます。最後に、切削のばらつきが加算されるのです。
数式だけからばらつきを考えてはいけません。実際の作業の中でばらつきの計算は決まります。
3+3+3+3=12 と 3×4=12 という計算はばらつきの計算をする上では異なる意味を持っています。
標準偏差とは
母集団を決めると平均値が決まります。
母集団を決めるということは、管理できる 同一条件の因子 と ばらつきの因子とを区別することです。同一条件の効果はばらつきませんから、データを合計しても消えません。いっぽう管理できていないことから起こるばらつきの効果は合計するとゼロとなり、ばらつき効果を消すことができます。
(重要)データを足し算すれば平均値の情報だけになります。
データを全部足し算すると、(平均値×n)の数値になりますね。これは、データを全部足し算すると、 ばらつき合計=0 となることと同じことを意味しています。繰り返して言うぞ。データを合計するとばらつきの情報は消えてしまいます。
(重要)平均値が算出できるからデータとの引き算で偏差が計算できます。
偏差とは管理できない、その他の無数の因子群がつくる効果のことを言います。管理できないからばらつきます。管理できるほうは平均値です。偏差の2乗は、データひとつのもつばらつきの情報量でしたね。で、全データの偏差の情報量を平均して一つのデータあたりの情報量としたのが分散ということです。 分散の平方根が標準偏差だね。だから、標準偏差とはばらつきの効果の平均的なおおきさであるといえます。 標準偏差とは何かを知るため同じことを視覚的(四角的?)に説明しよう。
Q: いろいろな大きさの正方形があります。この平均的な面積の正方形をどうやって描けばいい?
A: 全部の面積を合計して平均値を出し、その平方根を一辺とする正方形を書けばいいね。 標準偏差を計算する考え方はこれとおなじです。 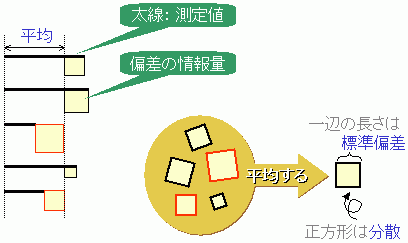
いま、偏差の大きさ(=個々のデータのばらつきの効果)を一辺とする正方形を考えます。すべてのデータは、いろいろな大きさの正方形を持っています。 正方形の面積は2乗した値だからばらつきの情報量の値になります。いろいろな大きさの正方形の平均的な面積をもつ正方形が考えられますね。この平均的な正方形の面積が分散で、そのときの正方形の一辺の長さ(=ばらつきの効果)が標準偏差です。
全部の正方形の面積を足し算したものが、平方和 S (または総分散)です。真の平均値から算出した平方和なら、平均するときにデータ数 n で割り算すれば平均の分散は算出できます。
エクセルの関数で、平方根は =SQRT(セル参照)で算出します。
または
fx(関数貼り付け)ボタン>数学/三角>SQRT>セル参照 または数値入力>OK
しかし上の自由度のところで説明したように、通常は試料からえられた平均値は真の平均値(母平均とも呼ぶ)からずれたものが得られます。通常は、測定値は全体の一部を測定するだけですから、試料平均値で算出された平方和は、真の平方和より平均値のずれ分だけ小さいものが算出されます。だから、平均するとき、データ数nで割り算せずに、平均のずれ効果分の1だけ小さい自由度 (n-1) で割り算することで、真の分散の推定値を算出します。自由度で算出した分散値は偏りがないため、不偏分散と呼びます。自分がどちらの平均値を使っているかで適用する統計手法が異なってきますから、次の対応関係をよくにらんで覚えていてください。
母平均 母分散 正規分布 Z(または u )値
試料平均 不偏分散 t分布 t値
統計手法では「母平均が既知のばあい」と「未知のばあい」とで違うのですが、「未知のばあい」は下側の試料平均の対応関係の標準化の式や表を使って行います。
通常の四則演算は母集団の平均値を決める
観測している同一条件下で2個以上のくり返しデータを取れば、管理できる平均値の情報量と、管理できないばらつき情報量が分離できます。 平均値とばらつきを分けるためには n = 2 、すなわち繰り返し試験をしないとばらつきは分離できない。繰り返しのない試験を数多くするより、繰り返し数が2であっても繰り返しのある試験のほうが早く真実に近づけることを知っていようね。日による変動も検出するには何日か日を変えて繰り返し実験をする。すなわち統計では繰り返しのある2元配置実験をすれば日による変動も分離できる。繰り返しのない試験を長くだらだら続けて何も結果が出ないより、集中的にやれば一発で方向を決定できるぞ。
観測している同一条件下での平均値は、母集団を設定すると決まってしまいます。母集団をあいまいにすると平均値の情報量と、分散の情報量があいまいになり測定結果も信用できないものになります。適当に拾ってきたデータから平均値や分散を計算してもあまり意味のある行為ではありません。
母集団のばらつき因子のなかに管理できる因子を発見して二つの母集団に分けるとどうなるでしょう。この作業を層別といいます。みんな知っているあの層別です。新しい二つの母集団に今までばらつき因子だった効果分がこれまでの平均値に加算されてそれぞれ別の平均値が出来ますね。同時に今までのばらつき因子から層別因子の効果分が減って標準偏差が小さくなります。
(注)
層別とは管理条件を一つ厳しくした母集団を作ることですから、それぞれの集団で新しい因子分だけ平均値が変わります。同時にばらつきはその因子一つ分だけ減少することになります。統計処理初心者は、こういう「どれが管理されているか」の視点で、2元配置分散分析の意味、繰り返しの意味などを考えると、他の統計処理全体の統一的な理解が早まりますよ。
小さくなったばらつきで平均値を比較する方が判断精度は良くなりますね。「分けることは知ること」と言った人がいます。分類整理する作業は、単純労働ではなく混沌からダイヤモンドを発見する方法なのです。 直感でよいから違う部分を見出し、層別して集計するという作業があたらしい視点を提示できるし、外部に発表できるような仕事ができる方法でもあるのです。
(ランダムと意図)・・・・再クリックで閉じる
統計処理を勉強すると、サンプルはランダムにとりなさいとか、テストの順番はランダムにしなさいというふうに教えてもらったはずだね。
その意味は、ランダムにサンプルを取らないと別の母集団が出来上がるということなんだ。層別と同じことがおこる。ある種の機械の性能を調べたいとしよう。機械Aと機械Bがあるとき、機械Aの製品ばかりサンプリングすれば、結果の平均値には機械Aの効果を含んだ偏った性能をしらべていることになります。
試食のテストをするとき、はじめに試食するときは空腹で美味しく感じられるが、後のほうになると飽きてしまって、普通の味だと感じるようになる。試食順序によって効果がかなり異なる。パネリスト全員に同じ順序で試食させると、はじめのほうで試食したテスト品が良い結果になる。
こうしたことを利用して組織内でサギ行為をする人も多い。統計でウソをつく人たちだ。母集団をはっきり意識することは、君がうそつきになるかならないかを決めるくらいの重要なことなんだよ。
社会ではデータがないと、どんなに良いことを言っても根拠がうすく感じられるため、口先だけの人になってしまいます。
逆に、組織内で統計数値を出して議論を進められると、何も検討せずに出席した人たちは反論しにくい。当然、資料を提出した人たちの思い通りにことが運ばれる。これを理論武装という。 企画部門の権力維持につかわれる定番の方法だけど、タコ国で勉強する君達はそんなことをしてはいけない。フェアでないと国や会社が疲弊するぞ。フェアを主張するあまり、一人で集団に対決するとつぶされるから気をつけてね。フェアな態度で再現性のある統計資料を作成することが、発言力と人望を兼ね備えることのできる方法です。
主成分分析にカテゴリー因子を入れることで、管理できる因子とそうでない因子を計算機で見つけることができます。世の中でデータマイニングといっている作業は主成分分析を使えば機械的にやれる作業に変わります。
タコでもわかる主成分分析で、積極的にカテゴリー変数を取り入れる理由はここにあります。データを見分けるセンスのないタコ人も出来るようにしたダイヤモンドを機械的に発見する方法なのです。
ちょっと視点を変えて、平均値も情報量の効果であるという話 上の図で、 a の因子を管理化して母集団とすれば AB が平均値となります。 AB2 が平均値の情報量であれば、 AE が b 、 c 、 d のばらつきを含めた観測値ということになります。 データ2合計 = 平均値2合計 + ばらつき2合計
このことを知っていれば、主成分分析で固有値が全体の情報の何%を回収したとか、回帰分析では決定係数から回帰が何%の情報を説明している等といった意味がわかるはずです。
主成分分析と因子分析の宗教論争は止めようね
「主成分分析は、ばらつきを考慮していないため分析法としては劣っている」という言い方をする人がいます。
ここまで学んできた人は、平均値とばらつきとは、合計という操作で情報量を切り分けたことを知っています。主成分分析は、軸の回転という方法で主成分スコアとそれ以外の情報量を切り分けた方法です。それ以外の情報量とは、主成分的にはばらつきに近い概念を持つ情報量です。
いずれも、情報量を2乗であつかう方法です。情報量の切り分けの考え方が異なるだけですから、その考え方の論議なしに、「主成分分析は母数の考え方が無いからダメだ」という議論は、軸を回転させることはいけないと主張していることになります。
情報量の考え方でなぜ測定値は正規分布をするかを理解していれば、このような議論はなくなるはずです。恥ずかしいし・・・。
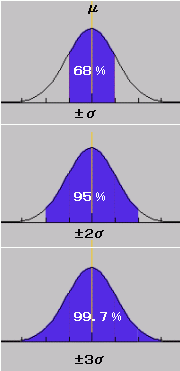
| 
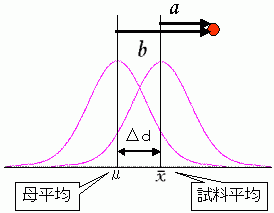 右図は N ( μ , σ2 )というある母集団から試料を取り、試料データから
右図は N ( μ , σ2 )というある母集団から試料を取り、試料データから