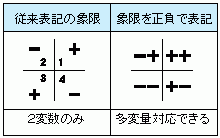
1 因子負荷量の符号から元のデータの相関係数の正負を予測
主成分分析において、2つの因子負荷量の符号を掛け算した時の正負の符号は、2変数間の相関係数の符号となる。因子負荷量の符号列から2変数間の散布図が正の相関か負の相関かは符号の掛け算だけで判断できる。
(例)
第2主成分の因子負荷量の符号は、 X3 は + 、 X5 は − である。
相関係数を計算しなくても X3 と X5 の相関係数の符号は − であることがわかる。
X3 と X5 の相関係数 : (+)×(−)→(−)
2 メカニズムの定性的符号表記
相関方向は変数間のメカニズムの数学的表記方法の一つである。
(例)
文章 「変数X1が増えると、変数X2は減少する。」
これを数学的な符号記述に切り替えることができる。→ я ( X1,X2 ) = я ( +− )
日常会話で話す程度の定性的なメカニズムの記述は、相関方向で表現できる。日常用語の動詞の変化方向を、変数値の符号の方向に対応させて置き換えると、メカニズムの会話表現は相関方向で圧縮記載できる。
この例程度の曖昧さで直線的に考えてよい部分的事象は、固有ベクトルの符号で扱ってよいことを意味しています。
相関方向は、メカニズムの定性的表記法です。
また、因子負荷量列は、主成分軸という直線への集中度の定量情報をもつ定量的メカニズム表記であるということを意味する。
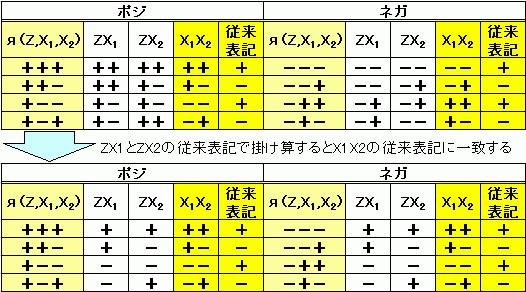
3 ポジとネガの同等性
メカニズムを言語で表すときに、人間が常識と対照的な表現になって考えにくい時に因子負荷量列の全部の符号をネガに切り替えてわかりやすい表現に切り替えてよいことを示している。(公式1)
(例)
変数(時間)の因子負荷量の符号が − なら、「時間が戻ると・・・」という表現になる。
分かりにくいから、この主成分の相関方向を全部ネガに切り替えて、変数(時間)の因子負荷量の符号を + として「時間が経つと・・・」という表現に切り替えた方がわかりやすい。
4 主成分特徴データの抽出
相関方向の符号表記は、偏差座標上では、重点からの大小で考えた時の象限の記号と一致する。だから多次元空間のなかで、相関方向の正負に合致するように、平均値からの大小で篩い分けするアルゴリズムだけで主成分軸のある象限に存在するデータだけを抽出できる。
この相関方向によるデータ抽出の技術は、実際でも役立つ性質です。 --- 再クリックで閉じます
たとえば、テレビ画像の色変化を大画面に換算する場面を考えてみましょう。ある画面の点周辺のミクロ領域を考えた場合にいちいち主成分分析計算して、主成分スコアを計算し、大画面の隙間空間の三原色を決定していたら変化速度に追随できません。相関方向の概念は、中間点と+−の符号だけで主成分分析と同じ作業をした結果が得られることをおしえてくれます。
ミクロ領域で相関方向分析をすれば、ミクロ領域では直線であつかっていても、ミクロの連続である大きな空間では、曲線をあるがままにあつかえます。さらに相関方向では、直線の座標に対する角度など考えてはいないことが解析のロバストネスを高めます。
斜交成分を分離しようとする独立成分分析でも曲線に対応できているわけじゃない。同じミクロの連続で勝負するのなら、主成分分析であっても、相関方向であっても、独立成分分析であっても、解析の結果にはそれほどクオリティ上差が出るということでもないでしょう。ならば処理の簡単なほうがよいはずです。
数式がでてくるとアレルギーがでるタコ人でも、こういう神々に対抗して解析結果では同等の結果をだすことができます。それは、主成分層別法を使って、あらゆる形状を目で確かめることができる「元の測定値間」の散布グラフを作ることです。
独立成分分析とその数式群に名前負けしてはいけないよ。解析の目標は、いかに自然のなかにひそんでいる情報を正確に把握するかということ。層別とグラフ化だけで、解析結果ではかなりのところまで神々と肩を並べるはずです。この二つに主成分層別散布図を入れれば十分!
数式を理解できるまで勉強期間が必要ですから、その間は、まずわがタコの主成分分析で学んだ解析で神々と対抗しながら時間稼ぎしよう。3章と4章で、数式を理解せずとも主成分分析の解析はできることがわかったでしょ。
データ抽出は、ポジ表現の象限と、ネガ表現の象限の2つについておこなう。二つの抽出データをあわせたデータ群が、相関方向データ群となります。
相関方向抽出では、主成分軸の存在する相関方向の象限に分布するデータを抽出します。原点に近いほど排除されやすいので、全ての変数について標準偏差以下の原点に近い所に分布するデータを相関方向抽出データに加えて、散布図にします。
相関方向抽出法の特徴は、凸凹の散布状態でも象限内にあれば描き出してくれます。
たとえば第1主成分と第2主成分の両方の特徴を備えていても、第1主成分あるいは第2主成分と分離することは出来ません。そのかわり相関方向に関してはありのままの散布状態を示してくれます。
第2章のタコ国の墜落した飛行機の事例で言うと、水平尾翼は、「胴体方向の第1主成分」と「主翼方向の第2主成分」の二つの主成分特徴を兼ね備えています。
主成分層別法は、主翼と水平尾翼は別々に分離して表示しますが、相関方向抽出法では同時に抽出されて表示されます。 主成分特徴を抽出する別の方法の、主成分層別法によるデータ抽出法は、主成分スコアが標準偏差以上の大きさのものを抽出しました。主成分層別法は主成分軸に沿って原点から遠くはなれた点だけを選択する方法です。主成分のみの散布図、複数の主成分性質を持つデータ群の散布図を分離して得ることが出来ます。
5 変数選択後の扱い
主成分分析の因子負荷量で、主成分に関係する変数を選択できる。 排除された変数はその変数が導入されても軸の回転にほとんど影響を与えない変数であることを意味しているので、因子負荷量列からその変数を排除した縮小因子負荷量列の符号を、変数選択された相関方向としてそのまま使っても結果に大差ないことを意味している。
微妙な因子負荷量値が、取り上げた変数以外の技術の常識から判断しても、メカニズムにおいて重要な役割を有するのであれば、変数排除されたデータ群でもう一度主成分分析をやり直せば正しい値での判断ができる。
外部発表するような場合は躊躇なく変数選択後のデータから主成分分析を試みるべきです。
特にカテゴリーデータを導入した主成分分析では、もしカテゴリーデータが重要な因子として選択されてきたら、そのカテゴリーで層別したデータ群を個別に主成分分析するとよい。
新しい情報が入手できるでしょう。
よく言っている意味がわからんというタコ人は、とりあえず元の観測データからカテゴリーごとの通常の層別散布図を作成すれば研究報告で大きな間違いを起こすことはないはずだから安心してね。
|