この質問は、定番の質問です。そしてあまり明解な答えを返す人がいないのも定番です。
このような質問をする人はもうタコ人じゃないから、数式抜きでもそれなりのレベルで回答せざるを得ないね。
この質問をする人の気持ちを察するに、多変量ソフトパッケージには、主成分分析と因子分析が並んでいて、説明にはどちらも因子なんて言葉がつかってある。どっちを使うか選択できないじゃないか。今まで習ってきた知識でも分かるように教えてよ。という声だろうね。
よろしい。まず、言葉のイメージだけで哲学論議するのは止めたほうがよい。
主成分分析を計算するときに次のことを行っています。
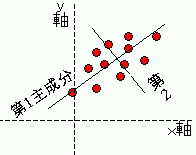
1 (測定値群) 空間に散布図をつくる
2 (軸の移動と回転) 散布のひろがりのあるところに直線をかく
3 (主成分スコア) 散布点からその軸に垂線を引く( = 射影する)
だから、主成分分析では座標軸を回転させて、散布点を回転後の軸からみえる値に換算しなおすだけです。適用するデータは、統計で求められる正規分布である必要はありません。
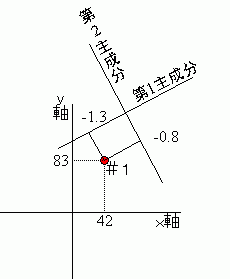
射影とは回転後の直交軸に垂線を下ろすことです。垂線が交わる直線上の値が主成分スコアです。(イラスト説明が必要なら簡略版へ)
主成分スコアを求めるには、原点の移動と軸の回転があるので、最初の測定変数全部を使った方程式が必要です。
もとの変数群にそれぞれ係数(重みまたはウエートともいいます)を掛け算して算出します。 原点が変わったため x と y に共に換算係数を掛け算して新座標系にあわせないといけないんだ。主成分スコアは二次元の場合次の式で計算されるよね。
主成分スコア = ax + by
このときの 元の変数にかかる係数 a、b を固有ベクトルと呼んでいる。変数に掛け算する固有の換算係数という意味なんだ。
散布図の中にプロットした点の集中している部分に回転軸を寄せてゆくこの作業が主成分分析です。
すなわち主成分分析では測定値の多次元散布空間に主成分の軸が直線として出来上がります。そしてその直線を方程式であらわしたものが、主成分スコアです。
元の測定変数群から方程式でひとつの指標(主成分)を計算することから、主成分スコアの式の意味を次のような表現で説明することが一般的です。
合成変数をつくる。縮約する。総合指標を作る。総合化する。新たなファクターを導く。など。
ひろがりのあるところに軸を設定する特徴から次のような表現が出てきます。これは軸の移動と回転に当たります。
情報の損失なしに・・・。最も固有値情報を取り込む・・・。合成変量の分散の最大化・・・。
また主成分分析ではひとつの主成分( = ある軸)の取り込んだ分散和である固有値が1以下になると意味が少ないと無視する解析手順をとります。このため次の表現が出てきます。
少数の総合指標にする。縮約する。集約する。要約する。
主成分分析はフランクフルトソーセージに棒を挿すような、一番データの広がった所に主成分軸を設定してゆきます。このことで、因子を集約する方法と説明されるのが、主成分分析とはという質問への一般の説明となっています。
何も主成分分析は、巷で言われている、因子集約の方法だけではありません。
我々は観測データがグラフ上で線状に並んでいたら、 x と y とに相関があると考えます。同じように多次元の空間でも、点が線状に並べば幾つかの変数間には相関があると考えます。
この変数間に順序情報を加えると、メカニズムとなります。たとえば「 A が増加すれば B が減少し、最終的に C が発生する」といった関連の表現です。
このメカニズムにタイトルをつける行為が主成分軸の意味を考えることなのです。
主成分分析でもっとも重要な部分は、「算出される因子負荷量行列は、メカニズムの数学的表現である」ということを理解することです。そして、因子負荷量の絶対値の大きさで、関係の薄い変数を排除できますから、メカニズムに参加する役者としての因子が選択できるのです。 主成分分析は、複数のメカニズムが分離でき、それぞれの変数選択ができる方法です。
わがタコ国では主成分ごとにその主成分が意味するメカニズムを因子負荷量から説明出来るようにしています。このとき、影響度におうじて測定変数を取捨選択することができます。その手順は3章で説明しています。また、その理論は9章の相関方向分析で説明します。
主成分分析は重心にまで原点を移して、いちばん広く見えるところに軸を入れていくという作業で出来た新座標系の位置に観測データを換算しているだけ。誤差なんか考えていないし、たねも仕掛けも無いのさ。
データの採取方法が無計画でいびつだったときでも主成分計算はできるから、このようなときにはメカニズムではなくいびつさを検出することもあることを知っておいてください。
いっぽう因子分析は、最初にデータの構造を仮定してしまう統計的やり方なんだ。共通因子と誤差分である独自因子とを分けられると仮定して計算方法を組み立てたやり方です。 因子分析は最初に主成分分析で初期値を計算したりするし、空間で軸を回転して情報量を分配するという点では同じだから誤解が多い。「情報量を分配するのが同じなら同じ方法」というのなら、分散分析だって重回帰分析だって全ての統計の手法は同じという言い方になります。
収束の条件(情報分配の考え方)が異なっているから、主成分分析と因子分析は別物です。 だから、座標軸を移動・回転させて空間上の位置をその座標系に数値換算しただけの主成分分析とは違う方法だよ。 統計的にデータの構造を仮定するということは、観測データが正規分布するということを前提にするので、因子分析は全部の観測データが正規分布することを前提にしています。
だから、カテゴリーデータなどの処理は因子分析の場合いろいろ考える必要が出てきます。 この仮定を無視して因子分析を計算することはできるけれど、そういう場合には意味のない活動をしていることになるよ。
無い物をあるように言いたいときはいいかもしれないが。
測定データ (観測データともいう。ある生徒達のテストの点数など) にはなにか全生徒達に特別の共通因子 (生徒の頭のよさとか集中力など) がいくつかあると仮定するんだよ。共通因子の大きさを因子スコアというんだ。
それぞれの生徒の測定データ値は、因子スコアに対して、±1の範囲での何%かの重みをかけて、全ての共通因子×重みの数値を合計したものが、測定データにかなり近づくように決められる。 測定データと「共通因子×重みの数値を合計」の差が誤差として扱われる。心理学から出発しているから、誤差とは言わず、独自因子などと称するようだ。まあ、分散分析などの誤差も取り上げた因子以外の独自因子群効果とは言えるけどね。
この重みの係数のことをを因子負荷量というのだよ。全体の誤差が一番少なくなるように、重みを計算で出そうとするんだけど、この因子負荷量も共通因子もどのように考えても正解というしろものだから、何かの規準をきめてコンピューター上で何回も計算してはどっちがいいかなーなんて判断しながら回答を絞っていくというやり方をとるんだ。
因子負荷量がおおきいということは相関係数が高いのとおなじだから、因子負荷量が0から離れる方向で何度も計算してはやり直しという作業をする。人手でこの計算をさせると、きっと助手も辞めていくことだろうから、コンピューター時代のやり方だね。
さて、因子分析はどのようなときに使うかの質問だよね。たとえば、子供達に共通の能力というものが確実に予見されるなどという確信があるときは因子分析は有効な方法だよ。その能力が国語の読解能力にも家庭科の能力にも野球の能力にも関係しているのならいいかも。
頭のいいやつのほうがスポーツも大成するって言うだろ?「頭のいい」という何かの共通因子が仮定できればいい方法さ。頭のいい程度を数値にできればいいよね。(個人的にはイヤじゃけど)
ボールのキレがいい、キレ味すっきり○○〇ビール、体のキレがいい、尿のキレがいいなどは、言葉が同じだけど共通の因子など仮定できないようだから因子分析はつかわないほうがいいかな。
(科学的姿勢)
言葉で勝負する人たちはこういう論理展開をする人が多いけどね。大辞典「〇〇」をひもとくとこう書いてあって、だからこう言えるといういいかたで議論する人たちは、因子分析も主成分分析でも因子を扱えることから同じ土俵で議論してしまうんだよね。
落語やコントなど言葉のあそびのときはいいけれど、真理探究には向かないね。
お釈迦様が弟子のアーナンダーに呼びかけたことばがある。「なあ、アーナンダーさんよ」。
このことを仏典には「南無 阿弥陀 仏」とかいてある。お釈迦様がアーナンダーさんにかたりかけた記録が仏典でもある。
推測や言葉の哲学的議論だけをやりつづけると南無阿弥陀仏に特別の意味を作り出し、ある宗教のように太陽が地球を回っていることになるし、ある種の統計信者のように因子分析と主成分分析はどちらがいいかなんて不思議な議論もでてくるな。
因子分析がはじめから使える状況というのは、はじめから因子モデルが仮定できるということだから、創造的分野というより、かなりその事実がわかってきている分野なんだ。
残念ながら人間の頭脳構造は、全てを予測して因子モデルを構築するようにはできていない。 いっぽうの主成分分析は、尺度や、分布や、直線性を深く考えずに済むから、未知分野でとりあえず最初に因子間の関連を眺めるのに適している。
それでも、因子分析でやりたいというひとは、なんか分からんが、とりあえず因子分析をしてみた結果をあれこれ考えることで、様々な仮説や考えるヒントがえられる。昔はこれを試行錯誤といっていたけど、今は前向きに探索的研究と言っているな。
取り合えずやってみることは、人間にとって必須の活動なのだよ。やってみなはれ。ただ、この段階で外部発表するのはやや問題あり。理由はまだ気づいた段階でしかないから。気づいた仮説を証明するには、どのような補助調査とか測定をしなければいけないか、調査計画を再設計する必要があるのが普通だ。良心的な調査会社は、まず小さい調査で大まかな仮説を立てた後に本調査を行う。
データをとりあえず因子分析にかけてみた結果、因子負荷量で何とか説明がついたからそれでいいというやりかたは、探索的とは言わないね。因子分析というヨロイをまとい、探索的という言葉で飾ってはいるけれど、手じかにあるデータの集計をしました、という程度の活動です。
よく因子分析の事例として、生徒の色々な科目の成績を解析した事例があるよね。もし学会発表するなら、例えばさらに道徳の試験成績を入れて同じ傾向の結果が得られるかどうかのチェック活動をすべきなんだ。え?ちゃんとやってるぞって?ごめんね。
入社したら、SPSSなど便利な統計計算ソフトがすでにあって、使い方を教えてくれる先輩がいるんで、分けわかんなくても因子分析も主成分分析も計算しちゃう事例が増えています。
時代のもたらす危機感ということで、許してね。
特に因子分析では、因子軸を回転させてもっとも中途半端さのない(0に近い値が少ない)因子負荷量を選択するようにしている。
言葉で考える人間にとって、これはとても理解しやすい条件なんだ。主成分分析では0.4とか0.5とかいった中途半端な因子負荷量が多くどのように説明してよいか分からないことが多いため、因子分析のほうを好む人たちが多い。しかし中途半端な因子負荷量は、他の主成分と切り離せない関係があることを教えてくれる重要な因子群なんだよ。
中途半端な因子負荷量の性質と取り扱い方を研究することが今後の研究の方向として重要になるはずです。
人間達は、この段階で決定的なことを忘れがちなんだ。因子分析で最初に仮定した構造式はそっちのけで、選択されてきた因子負荷量が分かれば、その解釈に走ってしまうという行動をとってしまう。大好きな言葉の遊びの世界で自分が参加できるからなんだ。
でもここが大事なんだけど、それではまだ因子分析をしているとはいえない段階なんだ。
主成分分析は、散布図上で人間のもっとも素直なやり方を軸の選択方法に使っている。すなわち楕円形に分布している場合には、フランクフルトソーセージの棒が挿される方向に軸を設定する。いちばん広がっている方向に線を引くという行動は人間のすなおなグラフ理解方法と一致している。
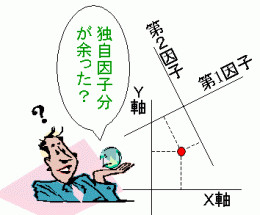 一方バリマックス回転などコンピューターに軸の方向は任せてしまって、算出される因子スコアは、最初の座標軸と直接1:1の関係ではなく、独自因子という誤差分を差し引かれた値なんだ。あいまいな値の因子負荷量がなくなったからといって、機械があいまいでなくなるように適当に誤差分を差し引いて算出したものなのだよ。
誤差分として適当に機械が差し引いたベクトルの中で因子負荷量を値をゼロか±1に近くするという規準というのは始めの座標で考えたときにどのような回転位置で止まっているのだろうか。独自因子分を差し引いているから単純な軸の回転ではありません。
う〜ん、考えれば考えるほど解釈困難になるな。因子負荷量は解釈しやすくなっても、因子分析本来の解釈は難しいのだよ。
因子負荷量だけで解釈する因子分析の大方の解釈方法なら、別に因子分析でなくても主成分分析で軸の回転を施し、もっとも中途半端でない(0に近い値が少ない)因子負荷量を選択するようにするほうがわかりやすい。マシンが設定した誤差分などないから、解釈は単純です。しかもそのスコアの空間分布は初めのままなのです。
因子分析をしていますというなら、その次の段階が因子分析なの。
因子分析の存在理由は、共通因子の発掘にある。因子スコアの推定まで行って初めて因子分析をしましたといえる。
構造式を指定するというのは、新しく発見できた因子は次に観測したときにも同じ大きさの値を示すということを仮定している。再現性が必要なんだ。
次回に観測したときにはなくなってしまうような因子は、因子分析で仮定されている因子ではありません。いくら「権威ある統計ソフトのSPSSで計算して出てきました」といっても、再現性がなければそこで計算された因子とはいったいなんだったのか、だれも解答が出せない。
因子分析で因子を発見しましたというときには、再現性のチェックが必ず要求されるんだよ。
いっぽう、主成分分析でも主成分を新しい集約された指標として主張する場合にも同じ再現性が要求されます。データの取る範囲や密度でころころ変わる主成分軸の方向のことはもう知っているよね。データの採取方法で軸がころころかわるという点は因子分析でも同じです。次回に同じ調査をしたら、軸の位置が全く変わってしまいましたということでは、その指標ってなんなの?という事になります。 因子スコアの大小は、現実のなかの現象を説明しているはずです。だから因子スコアは現実に起こっている測定値の大小を説明できなければならないんだ。それに加えて、何回調査しても同じ数値になるという再現性があることが示されなければならない。それが正しい研究成果というものだろ?
因子軸や主成分軸を再現性のあるものにするというテーマは、因子分析と主成分分析の方法の優劣の問題ではなく、調査計画や試験計画の網羅性、均質性など人間側のデータのとり方の問題になります。とくに因子分析には再現性を保つために、この網羅性、データの均質性は特に強く要求される事項となります。
しかし主成分分析を、ただの多次元の散布図として利用するときには、散布図の読み取りかたを示すだけだから、強く再現性を要求されることはありません。統計とは関係のないばあいでもグラフを学会報告で提出し、目で見てグラフから「経時的に増加しています」といったような解釈をするよね。ただの多次元の散布図として利用するときには従来どおりの「結果はこうだった」という程度の範囲での責任を持てばよいのです。
どちらかいうと、主成分分析は、仮定するモデルがなく、誤差など考えずに単純に回転させた軸からながめた多変量空間の散布図でしかないから、なんにでも適用しやすいという利点がある。
人間は4次元以上の空間の散布状態など想像もつかないんだから、主成分分析が教えてくれる情報から、人間用に情報翻訳するのが主成分分析の使い方といえる。二次元の散布図を使う感覚で、情報翻訳の手順に慣れればいいんだよ。 統計など知りたくもない一般の人達(決定権がある人が多い)に結果を伝えるには、プレゼンテーションとして2次元とか3次元グラフまでしか使えないんだから、どうしても最初の観測データから2次元の散布図をたくさん並べて説明することになる。そのときに主成分分析は必要な因子を指定してくれるから余計な散布図を作らなくて済むね。
それは見る人によけいな雑音をいれないということだし、その後の研究の混乱も減少できる条件になっているはずだよ。
全部の変数の組み合わせで散布図マトリックスをずらっとならべて仕事をしましたというのと、因子を選択した状態で意味のある因子群を散布図にするのでは、仕事の質がぜんぜん違うと思う。
多変量解析ソフトはどこの会社にもある時代になってきたし、神田さんのように無償で提供してくれる素晴らしい人もいる。いつでもデータはだせるから、無意味な統計報告も多くなっているよね。でもそれじゃあ、分からないコンプレックスはいつまでも消えないし、影で統計処理なんて何にも出来ないなんて意見を言うようになる。 真理の探究は楽しいことなんだ。誰も知らなかったことを自分の手で明らかに出来ることは、自分に誇りと自信と楽しみをもたらしてくれる。
本当は統計処理は色々な役に立つことが出来るのに、つかいこなせないだけなんだよ。
その証拠に、統計処理は何にもできないという人も平均値は使うよね。平均値が統計処理で基本の構造になっていることを知らないといっているようなもんです。
主成分分析は、多次元空間を覗くには必須の方法だと考えて下さいね。
| 
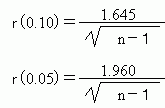
 何か見覚えがあるよね。そうピタゴラスの定理。
何か見覚えがあるよね。そうピタゴラスの定理。