主成分分析は英語では PCA: Principal Components Analysis といいます。
主成分分析だけだと、それは主成分スコアの計算方法です。
一般に言葉では次のように説明されます。すべて同じことの説明です。
<主成分分析で行うこと>
|
■ 主成分分析とは
多次元の空間でも同じです。データの点々が散布しているとき、平均値を中心にして、全部の軸をグルグル回転させていちばん広がっているところで軸を決めてゆく計算をしているだけです。軸はすべて直交しています。
詳細な行列計算を知らなくても主成分分析の解釈は可能です。
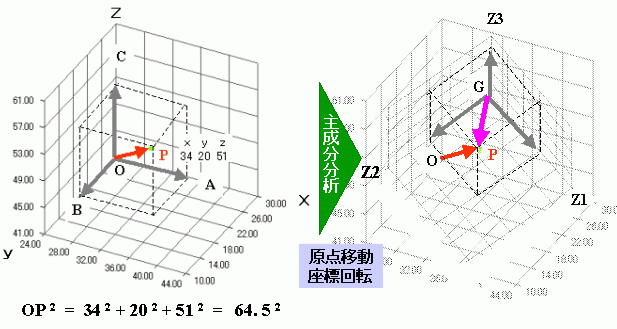
次の図は点 P( x 、 y 、 z )= P( 34 、 20 、 51 )の座標位置を示しています。
OP(赤矢印)がこのデータの全情報量で、64.52の大きさを持っています。この情報を x 、y 、 z のそれぞれの情報量に配分すると
x2 = 342 (OA)、
y2 = 202 (OB)、
z2 = 512 (OC)となります。
主成分分析をすると図では右のようになり、原点Oが変数の平均値である重心Gに移動します。
さらに点Pも含めた全体の散布点において一番広がっている方向に軸が回転して移動します。新しく出来た回転後の軸 Z1 、 Z2 、 Z3 が主成分軸です。
そして、GPを新しい座標軸に射像した値(右図グレーの矢印)が点Pの主成分スコアになります。
各主成分スコアの計算は、はじめに観測した変数 x 、 y 、 z の関数式から計算されます。そのため、関数式の x 、 y 、 z に係数が掛かりますが、 Z1 軸の射影値が求まるように係数の値が決まります。その係数が固有ベクトルです。すなわち、それぞれの対応する変数の固有ベクトル値と対応する変数値と掛け算して全部足し合わせたものが主成分スコアとなります。係数値は主成分計算したら自動的にプリントアウトされてきます。
この主成分スコア計算の意味するところは、「新しい総合指標を求める」ということです。一番広がったところに主成分直線を描くという性質によるものです。
《ちょっと知っているといい話》
- 主成分分析は平均値同士の比較は行っていない
- 主成分スコアで研究結果を論議するときに必要な注意点があります。OP(赤)がGP(ピンク)になったとき、平均値の情報量は抜き取られてしまいます。だから主成分分析は平均値比較は行っておらず、変化量どうしの関係を見ていることになります。研究報告などでは平均値比較情報として観測データ間の散布図は必ず入れて、考察に加える必要があります。
- 主成分分析はばらつきを考慮している
- 一般の統計解析方法は、正規分布のパラメーターである平均値と偏差の性質を利用して平均値効果とばらつき効果を分離しています。これを情報量の配分といいます。
主成分分析は単に軸の回転と射影で情報量の再配分をするだけですから、様々な尺度のデータを混用しても理論的には何の問題もありません。 主成分分析は射影が個別のベクトルのばらつき効果そのものとなります。
だから一般に議論されているように、「主成分分析にはばらつきが考慮されていない」という主張は、理解不足ということになります。
次の図は、主成分分析の利用のしかたがどのように違うかを図示したものです。もとの観測データにもどってそのメカニズムを考えようという思想の違いを示しています。
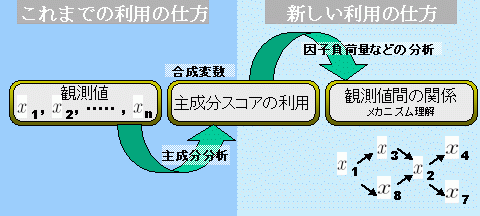
主成分分析を主成分スコアの計算方法とだけ考えるやり方は、古い考え方です。大学の授業な ら主成分分析法の計算方法だけ教えればよいので、こうした説明で十分です。しかし現実の社会の中で主成分分析を応用する場では、こうした理解だけでは不十分です。
実測される観測データ群から、スイッチ、ポンで、これまで世の中にない概念も主成分スコアとして計算されてきます。これまで世の中にない概念も算出できるため、直接測定できないような新しい指標を求める心理学、経済、経営などの分野で多用されてきました。
それは、対数の計算方法は知らなくても、関数電卓の logキー ひとつで対数値が計算できる感覚です。
すなわち、主成分スコアがどのような意味を持つかを知りさえすれば、主成分分析結果は行列 式の計算の意味など理解しなくても主成分分析は使えるわけです。だからこのサイト、タコ国では主成分分析の計算式などは記載していません。主成分スコアの計算方法なら、他のサイトに詳しく書いてありますからそちらを参照なさってくださいね。
身の回りにあるあらゆることで因果関係のある事象を、数値的に証明するといったことが考えられます。また、起こっている現象を分類してしまうこともできます。データマイニングなんて主成分分析で機械的に出来ることです。
このタコ国で説明する新しい主成分分析の使用方法はもとの観測データにもどって考えるやりかたですから、これまでのグラフや表の作成方法で対処できます ♪
■ 次世代の主成分分析の利用法とは
- メカニズム提示
- 同時に算出されてくる因子負荷量(主成分負荷量という人もいる)を手がかりにして、実測さ れる変数間の因果関係(メカニズム)を抽出できます。
- メカニズムの分離
- 数種のメカニズムが混合している場合に、メカニズムも個別に分離してくれます。
- 変数選択
- あるメカニズムに関係のない変数と関係のある変数をよりわけることができます。
- データマイニング指針提示
- 層別データとか分類型のデータはカテゴリカルデータと呼ばれています。主成分分析にカテゴ リカルデータを取り入れると、多くの変数の中から層別すべきカテゴリカル変数だけを選択し てくれます。
しかし、主成分分析は万能ではありません。メカニズムが直線関係にあるという条件のもとで しか、こうしたことはできません。これまで主成分分析を利用してきた人は、こうしたことを 知っていても知らなくても利用してきたわけですから、社会では、こうした前提を受け入れて います。
というより、むしろ魔法の多変量解析だからコンピューターが計算した結果に誤りはないとい う信じ方で運用されてきたきらいがあります。人間の心理過程は決して直線ではないですし、 経済だって、規模の限界から来る頭打ちがありますから直線関係はありえません。
主成分分析だけですべてを済ませようとすること自体、より正確に現実の出来事を理解するに
は不十分です。
しかし、主成分分析を行った後に、その結果といくつかの他の手法を組み合わせることによって、主成分分析法は見違えるほどすばらしいデータ解析方法に生まれ変わります。
■ 主成分スコア計算後の分析方法とは
主成分スコアの計算をしたあとに行う解析とはどのようなことをするのでしょうか?
主成分分析後に、因子負荷量(主成分負荷量ともいいます)から選択されてきた変数間の2次元散布図を、無処理の元のデータ間で表示させて確認することはとても重要です。
何を確認するかというと次のようなことです。
佐藤の3次元バブル散布図(フリーソフト)なら、見やすい位置に自由に回転表示できるため、さらに次のようなことを判断できます。
確認事項のそれぞれが何を言おうとしているかわからない人は本文を勉強してください。少なくとも主成分分析で学会発表レベルの仕事をするつもりなら、間違った考察をして恥をかかないために必要です。科学者として大自然と真正面に向き合うために必要です。
主成分分析後に、必ず行う必要がある作業が、主成分スコアどうしの散布図作成です。この作業の中から、まず行いたいのが関数関係の有無の判断です。
関数関係がありそうであれば、主成分スコアを用いた回帰分析をおこないます。変数の次数や対数、逆数、または交互作用の有無の判断は、散布図から人間が判断します。
しかし、実際に観測されるデータ群では、主成分スコアだけから関数関係を見出せることは少ないため、次のような工夫をします。
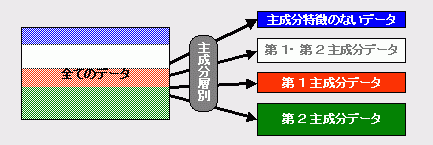
たとえば第1主成分のデータだけを抜き出してしまえば、以降の解析は今まで皆さんが行ってきたグラフ作成などのやり方で解析できます。
一般に使われているグラフや表などの集計ででてきた結果はそのまま第1主成分の性質ということになります。さらに回帰分析で第1主成分だけの方程式を作ることもできますね。
データ層別の方法は二つ提案されています。
- 主成分層別法
- 相関係数をもとに計算した主成分スコアなら、数値の大小でその主成分に関係するデータかどうかを選択することができます。その主成分で考えずに、その他の主成分の影響が強いデータを排除してゆけばよいのです。
具体的な方法は、第3章に説明しています。エクセルでの主成分層別マクロの紹介もしていますから、煩雑な分類とソートはデータのはりつけ作業をすればエクセルで行えます。
選別の基準は ±σ の範囲以外にあれば、その主成分の影響が強いと判断する方法をとります 。もちろん、いろいろな選別の基準が考えられますし、解析結果の使用目的にあった基準がこ れからもいろいろ出てくると思います。皆さんもチャレンジできる分野です。- おなじみのグラフや表類
- 主成分分析でデータを主成分ごとにより分けて、もとのデータ間の関係に戻すのですからこれまで使ってきたあらゆるグラフ類が利用されます。プレゼンテーションにも相手にわかりやすい状態に加工されていることが特徴になります。
主成分軸の存在する象限(相関方向)は因子負荷量の符号の正負に一致します。相関係数の正負の解釈を、多次元に拡大して解釈できます。
- 相関方向分析法
- 相関方向分析法は主成分の示すメカニズムの意味を因子負荷量から誘導するときに必要な知識であり根拠です。だからメカニズムを決定するためにつかわれます。
相関方向分析法は、従来では2変数の相関の正負で表現されていた概念を、多次元の変数に拡 張した概念です。相関を正負であらわすことができるのは2次元までですから、拡張表現を新しくつくらなければなりません。タコ国では第9章に説明しています。
主成分分析では直線でしか考えませんが、相関方向分析では曲線の扱いも可能です。そのため 、人間がひとまとまりの関係と考えた空間内のデータ抽出に利用できます。 計算そのものは、データと平均値の大小をコンピューターで象限ごとに選別させるだけの簡単なものです。- 重回帰分析法
- 相関方向分析法あるいは主成分層別法で抽出されたデータ群の曲線を方程式にします。詳細は第5章で説明
層別を行わない場合には。主成分回帰法となります。回帰分析が理解しやすいため主成分分析法より身近で、手法自体は重回帰分析法のほうが人気があります。
主成分分析で選択された変数(因子)群を使って重回帰分析をします。重回帰分析による変数選択法は、多重共線性という計算上の制約から、重要な変数から消してゆくという性質がありますので本質的な変数選択法ではありません。「関係のある」という言葉を排除して、「排除できるだけ排除して元の情報をできるだけかき集める」変数選択法であるということを知って いなければいけません。
検索エンジンから直接ここにきた人はフレーム目次つきタコ国が全体をみわたせて便利です。ここは第4章の下にある(おまけ)です。