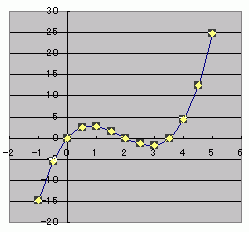
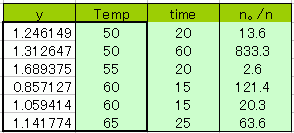
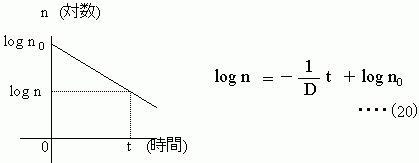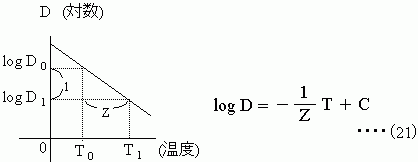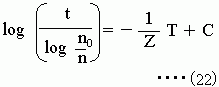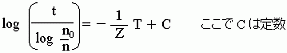重回帰分析では色々な式が作れるよ。log x、x2、x3、xy、1/xなど自由自在。
例えば、新しく log x の測定値をとるのではなく、すでに君が入力したデータ x から log x の計算値の列をつくるだけです。しかし、何を適用するかは君の技術知識とセンス次第だよ。理論的に導かれた式があって、それがどの程度現実とあっているかを調べることも出来る。 何も知識の無いタコ人には、とりあえずエクセルであれこれ適用してみて観測値といちばんよくフィットする式を選ぶ方法も取れる。 生物系や商品企画系の人々には、時系列でS字型に変化するグラフを適用したいだろうし、その方法も開発されている。
理論的に式を導びける神様たちには、あまり関数の当てはめの説明も要らないと思う。だから、他の人がこんなことに使っているのか程度に見ていただければありがたい。
さてタコ人むけ。最終的に次のような形に持ち込んでくれ。ここで、x1 とか x2 には、log x であろうと、単なるxであろうと、1/x であろうと,
さらには xy であってもかまわないんだ。+ でも − であってもいいよ。
y = ax1 + bx2 + cx3 + dx4 + ・・・・・・ +(定数)
この式に持ち込めたら、後は移項したりして式を変形していつも使っているような形にすればいいだけ。要点は上記の式の形状に出来れば、重回帰分析が利用できるんだ。
重回帰分析をすると、係数のa、b、c、d・・・などの数値が決定できるんだ。
例えば、y = ( xa・10xy ) / (b - 2) なら両辺の対数をとれば次のようになるだろう?
log y = a log x + xy - log( b - 2 )
log y→Y、log x→X1、xy→X2、-log(a-2)→C(=定数)と置き換えれば次の式になるだろ?重回帰分析で係数決定できることを意味しているんだよ。
Y = a X1 + X2 + C
エクセルに、君の入力した x と y の表があるだろう?その数値を使って新しく log y、log x、xy の計算欄を作って重回帰分析をすれば、係数や定数を計算してくれるから、それから見栄え良く変形したければ移項して元の式に変形するだけでいいんだ。
このまま重回帰分析すると xy の項に1以外の1近傍の数値が係数として選ばれてくるはずです。「理論的に xy の項は係数が 1 だから他の係数が入ってくることがどうしても嫌だ」という人は、次のように工夫すればよい。xy項を移項して
( log y − xy ) → Y とおきなおせば、次の式になるよね。
Y = a X1 + C
「できないじゃないか」と威張る前に「もっといい方法がないか」と自分で考える姿勢をもつのが大人ってもんです。
実験計画法などで交互作用項が検出されたりした場合には、交互作用項の係数も重回帰分析で計算できる。データの列に新しく、xy の計算をした列を付け加えればいいのさ。
また、3次元のグラフなどで、平面ではなく山が出来たグラフなどでは、xy項を付け加えてみると、重相関係数がぐっと上がることがある。
あ、重相関係数とは、多変数のときに使う相関係数のことで、2つのときはただの相関係数って言うんだ。(相関係数と重相関係数の詳細説明は、第8章へ。)
関数式で、分母に x の項がはいるような関係式にも xy 項を入れてみると良い。グラフが反比例の関係にあるときには、このような関係式を考えてみるのもよいはずだ。
主成分分析でお世話になった神田ソフトにも重回帰分析が入っていたよね。だから、第1章からずっとつきあってくれた君たちには何も特に準備しなくても、もう重回帰分析できる状況にあるよ。やり方も主成分分析とおなじ。
出力の中に偏回帰係数というところがあるよ。それがここでいっている係数のことだよ。
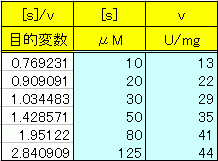
ただ、重回帰分析にはデータの入力にちょっと癖がある。気難しいんだ。目的変数といわれる項を表のいちばん左に書くとか、いろいろある。
ま、食わずギライもなんだから、とりあえずやってみようか。
|